
Oorlog uit Eerste Hand
Oorlogsbrieven (1935-1950) van het NIOD digitaal
Sinds de bevrijding in 1945 heeft het NIOD vele, vaak persoonlijke, documenten uit de Tweede Wereldoorlog verzameld. Een waardevol, vaak onderbelicht, deel van de NIOD-collectie bestaat uit brieven uit de periode van vlak voor, tijdens en na de Duitse bezetting van Nederland en de Onafhankelijkheidsoorlog in Indonesië (circa 1935-1950). Deze collectie oorlogsbrieven is binnen het project ‘Oorlog uit Eerste Hand’, dat plaatsvond in de periode 1 juli 2020 – 1 juli 2023, geconserveerd, gedigitaliseerd, getranscribeerd en beter toegankelijk gemaakt. De digitaal ontsloten brievencollectie biedt nieuwe mogelijkheden om historische vragen te onderzoeken rondom de emoties, ervaringen, verwachtingen, onzekerheid, stress en veerkracht van tijdgenoten.
Oorlogsbrieven
De oorlogsbrieven-collectie van het NIOD is bekend als 'collectie 247 correspondentie'. Deze collectie bevat onder meer brieven van vervolgde Joden, kinderen in onderduik, politieke gevangenen, verzetsmensen, displaced persons, vluchtelingen, oostfrontvrijwilligers of mannen in de Arbeidsinzet. Hoewel hun situaties zeer uiteenlopend waren, schreven zij allemaal (soms ver van huis) brieven naar hun geliefden, hun ouders, soms naar vrienden, bekenden of familie elders on the move. Omgekeerd schreven de vaak verontruste thuisblijvers brieven aan hun geliefden ver weg. De brieven laten zien hoe mensen vormgaven aan hun ervaringen en aan onderling contact in oorlogs- en bezettingstijd. Ze geven een beeld van het leven in een onzekere periode van geweld, bezetting, oorlog, onderdrukking, vervolging, verzet, collaboratie en schaarste - een leven waarin vrijheid en democratie vaak abstracties waren. De collectie als geheel is in november 2022 officieel opgenomen in het Nederlandse Unesco Memory of the World register.
Project
In het eerste jaar van het project ‘Oorlog uit Eerste Hand: Oorlogsbrieven (1935-1950) van het NIOD digitaal’ zijn de oorlogsbrieven geconserveerd en gedigitaliseerd. Vervolgens zijn computermodellen voor automatische handschriftherkenning en -transcriptie ontwikkeld en toegepast. Dit proces wordt, in het geval van handgeschreven tekst Handwritten Text Recognition (HTR), en voor gedrukte of getypte tekst Optical Character Recognition (OCR) genoemd. Door OCR en HTR kunnen niet alleen mensen de tekst op scans gemakkelijker lezen, maar ook computers. De computer herkent de woorden op de scans en zo kun je als gebruiker de tekst doorzoeken op trefwoorden. In het laatste projectjaar is er een verrijkte en doorzoekbare digitale dataset gegenereerd die in onderzoek gebruikt kan worden voor de toepassing van kwantitatieve tekstanalyse. Dit maakt dat de collectie niet alleen beter bewaard blijft voor het nageslacht, maar ook beschikbaar wordt gesteld op een wijze die nieuwe onderzoeksmogelijkheden biedt.
Scans
Een belangrijk resultaat van ‘Oorlog uit Eerste Hand’ zijn de gedigitaliseerde versies van alle correspondenties, ansichten, briefkaarten, en kattebelletjes uit ‘collectie 247 correspondentie’ van het NIOD. Inventarisnummers zonder openbaarheidsbeperkingen worden online gepresenteerd als beeld (high-res scan) en als machine-leesbare tekst (transcriptie) op de centrale online verzamelplaats Archieven.nl. Het materiaal is (onder de rubriek ‘inventaris’) online raadpleegbaar via:
Transcripties
Door de beschikbaarstelling van door de computer te lezen transcripties zijn de teksten in de brievencollectie volledig doorzoekbaar geworden. Hierdoor is de gebruiker niet meer afhankelijk van alleen de metadata (archiefbeschrijvingen). Gebruikers kunnen nu ook op schaal de transcripties doorzoeken op onderwerpen uit het verleden. Ben je bijvoorbeeld op zoek naar informatie over communisten in oorlogstijd? Typ dan het trefwoord ‘communist’ in het zoekveld. In de zoekresultaten verschijnen niet alleen inventarisnummers waarin het trefwoord voorkomt in de archiefbeschrijving, maar ook inventarisnummers waarin het trefwoord voorkomt in de lopende briefteksten zelf. Omdat niet alles meer handmatig doorgenomen hoeft te worden, kunnen grotere hoeveelheden bronmateriaal meegenomen worden in onderzoek
.png?itok=AivNqON0)
Hier wordt een asterisk (*) in de zoekopdracht ‘communist*' gebruikt om niet alleen inventarisnummers op te roepen met het trefwoord ‘communist’, maar ook bijvoorbeeld ‘communistisch’, ‘communisten’, ‘communistische’.
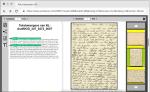
Wanneer je klikt op het downloadsymbool (zie bovenste pijl) kunnen scans (per pagina) gedownload worden. Heb je moeite met het lezen van oude handschriften? Wanneer je klikt op het tekstsymbool (zie onderste pijl) dan worden de transcripties leesbaar.
HTR-modellen
Binnen het project ‘Oorlog uit Eerste hand’ is gebruikgemaakt van Transkribus. Dit is een software-programma waarmee handgeschreven gedigitaliseerd archiefmateriaal - na een trainingsproces - automatisch door een computer getranscribeerd en gestructureerd kan worden. Wil je binnen Transkribus ook met automatische transcriptie aan de slag? Binnen het project ‘Oorlog uit Eerste Hand’ zijn twee hoogwaardige computermodellen gecreëerd voor automatische herkenning en transcriptie voor handgeschreven Nederlands uit het midden van de twintigste eeuw. Deze modellen zijn voor iedereen te gebruiken via de werkomgeving van Transkribus. Een online demo-versie is uit te proberen via:
- NIOD_WarLet_1935-1950_NoBasemodel https://readcoop.eu/model/niod_warlet_1945-1950_nobasemodel/
- NIOD_WarLet_1935-1950 https://readcoop.eu/model/niod_warlet_1935-1950/
Wetenschappelijke dataset
Een van de belangrijkste eindproducten van ‘Oorlog uit Eerste Hand’ is de getranscribeerde, machine-leesbare en verrijkte dataset met transcripten van alle scans met tekst uit het project. Deze dataset is met name interessant voor onderzoekers of andere geïnteresseerden die op een meer systematische manier met het materiaal willen werken en bijvoorbeeld computationele data- en tekstanalyse (‘text mining’) willen toepassen. Onder de naam ‘First-Hand Accounts of War: War Letters (1935-1950) from NIOD Digitised’ is het materiaal in verschillende subsets bij DANS gedeponeerd. Die zijn hier te vinden. De dataset bevat de volgende onderdelen:
- Beschrijving en link naar HTR-model ‘NIOD_WarLet_1935-1950’
- Ground Truth War Letters Transcriptions Dataset
- Dataset bestaande uit ongeveer 1000 pagina’s handmatig getranscribeerde, gecontroleerde en gecorrigeerde transcripten van oorlogsbrieven. De transcripten kunnen gebruikt worden voor historisch of (computer)linguïstisch onderzoek of voor het trainen van nieuwe HTR-modellen.
- War Letters (1935-1950) Transcriptions Dataset
- Deze dataset bevat alle (handmatige en automatisch gegenereerde) transcripten van scans van oorlogsbrieven uit het project ‘Oorlog uit Eerste Hand’ op verschillende aggregatieniveaus:
- Per inventarisnummer: 1480 platte tekstbestanden (.txt).
- Per pagina/scan: +/- 145.000 platte tekstbestanden (.txt) en +/- 145.000 gestructureerde en verrijkte ALTO-XML bestanden (.xml).
- Deze dataset bevat alle (handmatige en automatisch gegenereerde) transcripten van scans van oorlogsbrieven uit het project ‘Oorlog uit Eerste Hand’ op verschillende aggregatieniveaus:
- War Letters (1935-1950) Metadata Dataset
- Deze subset bestaat uit een matrix (.csv) met toegevoegde metadata op inventarisnummer-niveau. Deze matrix kan gebruikt worden voor zoek- en onderzoeksdoeleinden.
Het projectteam bestond uit Annelies van Nispen (informatie-analist), Carlijn Keijzer (beleidsadviseur collecties), Milan van Lange (onderzoeker), Sergio Leatomu (conservering) Muriël Bouman (onderzoeksstagiair) Financier: Mondriaan Fonds, VWS.



